When I joined a new organization I found there was really valuable research data from previous surveys as well as coming in from our user base through multiple feedback channels. But if it didn’t find its way into a current project that feedback and research was getting lost. We were not only losing opportunities to know our products and users better, but we were also wasting time (and frustrating our stakeholders) by asking the same questions again and again without acting on their responses.
A repository for our research data was clearly needed. I set out to research and build a solution.
Jira: the imperfect best choice
Ultimately Jira emerged as the best—if imperfect—fit for our research repository. The strongest draw for our team was distributed access to the data: the entire organization is already heavily invested in Jira for handling software tickets. We all use the platform on a daily basis, reducing barriers to entry.

Jira has limitations, but by building a custom project I controlled all fields and their parameters. I build the UXR hub around two basic data types: the Observation, and the Insight.
Our data is input as observations. Following Tomer Sharon’s atomized data philosophy the observation is the smallest functional size of a self-contained data unit. One user experience interview might generate anywhere from 1-20 — or more! — individual observations.
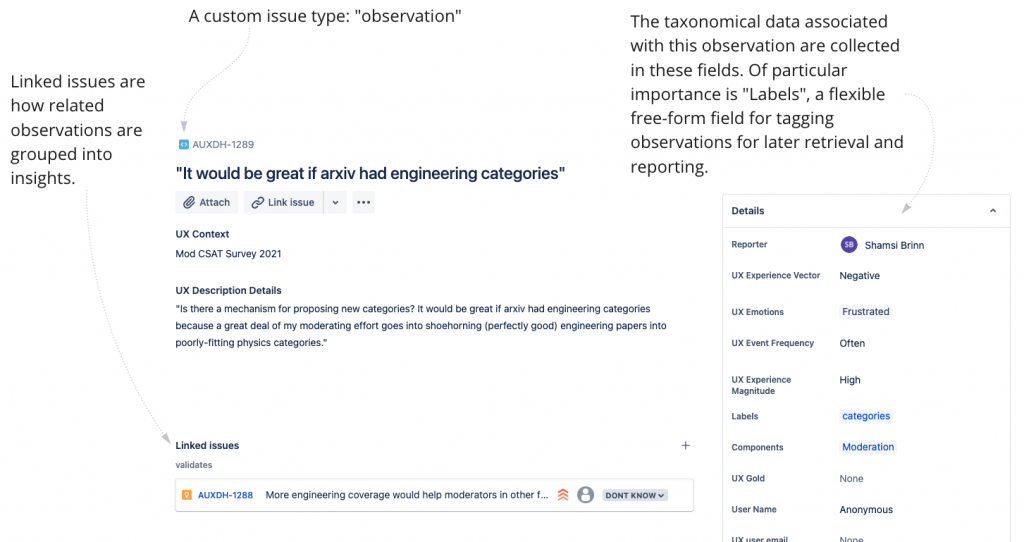
When patterns emerge from user observations, we create an Insight to group them. Insights follow the format of a freestanding report, and can be as simple and short as the example below, or much longer with attached addendum or stand alone analysis.
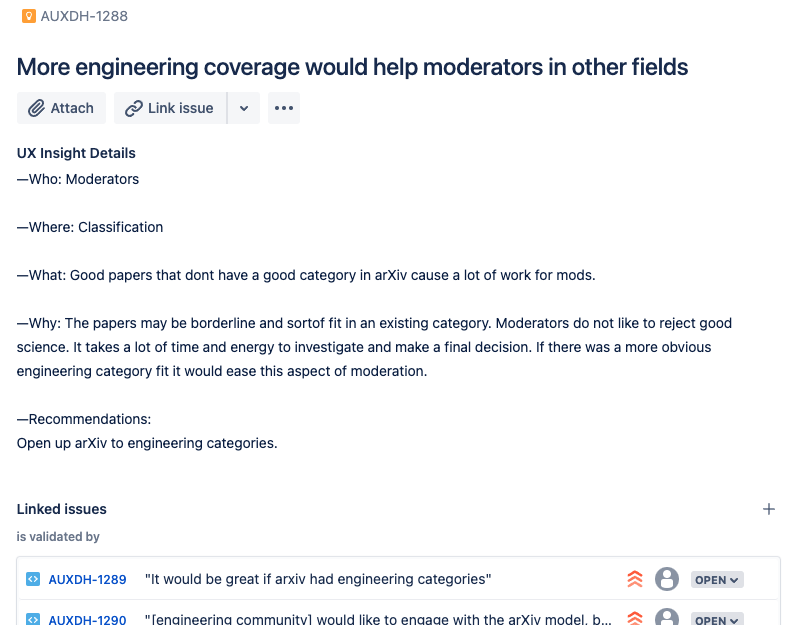
What sets insights apart from free standing reports, besides being readily accessible and easy to digest, is that they are are not static but dynamic; they are updated as new related observations are catalogued. By regularly grooming incoming observations and matching them to the insights they are validating or invalidating, we can ensure reports remain up to date with modest ongoing effort.
My in depth article on building a research repository using Jira can be found here.